-
Recurrent Neural Network기초_개념/Deep Learning 2020. 12. 31. 16:43
RNN
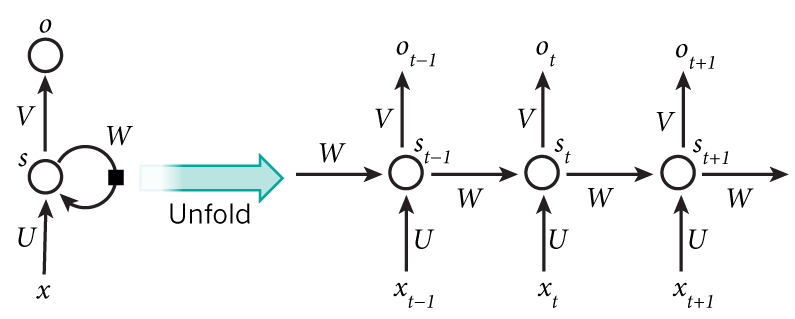
- RNN은 시계열 데이터에 대해 강력한 성능을 보여주는 뉴럴 네트워크의 한 종류이다.
- 기본적인 구조는 이전 타임 스텝의 출력을 현재 타임 스텝의 입력으로 사용하며, 모든 타임 스텝에서는 모든 파라미터를 공유한다.
- RNN이 시계열 데이터에서 강력한 성능을 보이는 이유는 구조상으로 이전 상태에 대한 정보를 일종의 메모리 형태로 저장할 수 있기 때문이다. 시퀀스 데이터는 앞의 정보가 뒤의 정보와 연관관계를 갖기 때문에 이러한 구조는 매우 유용하게 동작한다.
[출처] https://www.nature.com/nature/journal/v521/n7553/fig_tab/nature14539_F5.html BPTT
- Backpropagation Through Time
- RNN 계열의 뉴럴 네트워크에서 Gradient를 계산하고 Backpropagation 하는 방법을 의미한다.
- 뉴럴 네트워크 학습의 최종적인 목표는 파라미터에 대한 에러의 Gradient를 계산하고 이를 SGD를 이용하여 에러를 최소화할 수 있는 파라미터를 찾는 것이다.
- RNN 또한 기존 뉴럴 네트워크와 마찬가지로 먼저 Forward를 통해 각 타임 스텝별 시퀀스를 출력한다.
- 다음 이 출력 시퀀스와 손실 함수를 사용하여 각 타임 스텝별 Loss를 계산한다.
- 마지막으로 손실 함수의 그래디언트를 펼쳐진 네트워크를 따라 역전파를 진행한다.
- BPTT는 그래디언트가 마지막 타입 스텝의 출력뿐만 아니라 손실함수를 사용한 모든 타임 스텝의 출력에서 역전파한다.
- 이때 RNN은 모든 타임 스텝에서 매개변수를 공유하기 때문에 역전파가 진행되면서 모든 타임 스텝에 걸쳐 각 타임 스텝이 그래디언트에 기여하는 것을 전부 합산한다.

[출처] https://excelsior-cjh.tistory.com/184 - RNN 에서는 기존 뉴럴 네트워크의 역전파와 달리 타임 스텝별로 네트워크를 펼친 다음, 역전파 알고리즘을 사용한다.
- BPTT는 전체의 타임 스텝마다 처음부터 끝까지 역전파를 하기 때문에 타임 스텝이 클 수록 계산량이 많아진다. 이를 해결하기 위해 전체 타임 스텝을 일정 구간(일반적으로 5 step)으로 나눠 역전파 하는 것을 Truncated BPTT라 한다.
Vanishing Gradient
- RNN은 긴 시퀀스를 처리하지 못하는데 이를 Long-Term Dependency 문제라고 하며, 이는 입력 길이가 길어질 수록 과거의 정보를 전달하기 힘들어지기 때문에 발생한다.
- 그렇다면 왜 과거의 정보를 전달하기 힘들까? RNN에서는 t 시점에서의 결과를 얻기 위해 t-1 시점의 출력을 사용한다. 그렇기 때문에 그래디언트의 계산에 Chain Rule이 적용된다. 또한 각 타임 스텝에서는 non-linear activation function이 적용된 결과가 출력된다.
- tanh 함수와 sigmoid 함수는 양쪽 끝에서 미분값이 0으로 수렴하게 되며, 결과는 항상 [0,1] 사이의 값이 출력된다. 그렇다면 1보다 작은 값이 타임 스텝 t 만큼 곱해진다면 어떻게 될까? 당연히 0에 점점 가까워지게 될 것이다.
- 이 처럼 역전파가 진행되면서 그래디어트가 점점 0에 가까워지고, 먼 과거의 상태는 현재 상태에 아무런 영향을 주지 못하는 것을 그래디언트가 사라진 것과 같다고 하여 Vanishing Gradient라고 한다.
- 이는 RNN 뿐만 아니라 매우 깊은 DNN에서도 발생한다. 펼쳐진 RNN 네트워크를 90도 회전시키면 DNN과 유사한 구조를 보인다는 생각하면 쉽게 이해할 수 있을 것이다.
- 해결 방법
- Weight Initalization & Regularization
- ReLU Activation Funciton
- ReLU의 미분값은 x가 커지더라도 항상 1이 되기 때문에 Vanishing Gradient의 반대 개념인 Gradient Exploding이 발생하더라도 Gradient Clipping과 같은 해결책도 존재하기 때문에 더 좋다고 한다.
- LSTM ( Long-Short Term Memory ) or GRU ( Gated Recurrent Unit )
LSTM
- RNN은 비교적 짧은 스퀀스에 대해서만 효과를 보이며, 입력되는 시퀀스의 길이가 길어질 수록 앞의 정보가 뒤로 충분히 전달되지 못하는 Long-Term Dependency 문제를 갖고 있다.
- 아래 그림은 타임 스텝이 지나면서 각 타임 스텝에서의 첫번째 입력값 x1의 정보량을 색으로 표현한 그림이다. 뒤로 갈 수록 정보량이 옅어지는 것을 볼 수 있다.

[출처] 딥러닝을 이용한 자연어 처리 입문 - LSTM은 hidden state 계산이 복잡해진 RNN이라고 볼 수 있다. LSTM는 내부에 정보를 조절하기 위한 3개의 게이트와 타임 스텝의 상태를 저장하기 위한 Cell State가 추가되었다.
- 입력 게이트 : 현재 정보를 기억하기 위한 게이트로 해당 타임 스텝에 선택된 기억할 정보의 양을 정한다.
- 삭제 게이트 : 기억을 삭제하기 위한 게이트로 시그모이드 함수를 지나면서 삭제할 정보의 양을 결정한다.
- Cell State : 먼저 삭제 게이트를 통해 결정된 삭제할 정보의 양에 따라 정보가 손실된다. 이후, 입력 게이트의 결과값과 더하여 현재 타임 스텝 t의 셀 상태가 된다. 이 값은 다음 t+1 시점의 셀로 넘겨진다.
- 출력 게이트 : 출력 게이트는 현재 타임 스텝 t의 x값과 이전 타임 스텝 t-1의 hidden state가 시그모이드 함수를 지난 값이다. 해당 값은 t 시점의 hidden state를 결정하는 일에 사용된다.
- hidden state : 출력 게이트의 결과값과 tanh 함수를 거친 Cell State를 연산하여, 정보가 걸러진 hidden state를 얻을 수 있다. 이렇게 얻은 hidden state는 출력층과 다음 타임 스텝의 셀에 전달된다.
- 때때로 hidden state는 단기 상태로 Cell State는 장기 상태로 부르기도 한다.

[출처] 딥러닝을 이용한 자연어 처리 입문 GRU
- GRU (Gated Recurrent Unit)은 LSTM의 구조를 간결하게 변경한 모델이다.
- LSTM과 마찬가지로 Gate를 통해 정보의 양을 조절하는 것은 동일하지만 방식에 차이가 있다.
- 구조적으로 보면 GRU는 LSTM의 삭제 게이트와 입력 게이트를 결합하여 Update Gate를 만들고, cell state와 hidden state를 하나의 hidden state를 묶은 것이다.
- Reset Gate : 이전 hidden state의 값을 얼마나 활용할 것인가?
- Update Gate : 과거와 현재의 정보를 각각 얼마나 반영할지에 대한 비율을 결정한다.

'기초_개념 > Deep Learning' 카테고리의 다른 글
Optimization (0) 2021.01.11 정규화 (0) 2021.01.05 Dialog Management (0) 2020.12.30 Neural Network Bias (0) 2020.12.26 Gradient Descent & BackPropagation (0) 2020.12.23